- US - English
- China - 简体中文
- India - English
- Japan - 日本語
- Malaysia - English
- Singapore - English
- Taiwan – 繁體中文
Micron is and has been deeply committed to making world-class SSDs for the data center. We have shipped tens of millions of SSDs into data centers to date and are ramping new SSDs with our 232-layer NAND technology. A world-class SSD includes not only attributes of power efficiency and high performance, but also design resiliency. Resiliency means the drive will have a long and useful life in its data center home.
Defining high resiliency has been a topic of the OCP Storage Workgroup in collaboration with device and host manufacturers. The OCP Storage Workgroup has refined and enhanced vertically integrated high-resiliency over the three major releases of their Datacenter-NVMe-Specification (which I’ll call the “OCP SSD Spec” for the remainder of this article). Vertically integrated resiliency is a concept that means both the host and device take on elements of making a highly resilient storage subsystem.
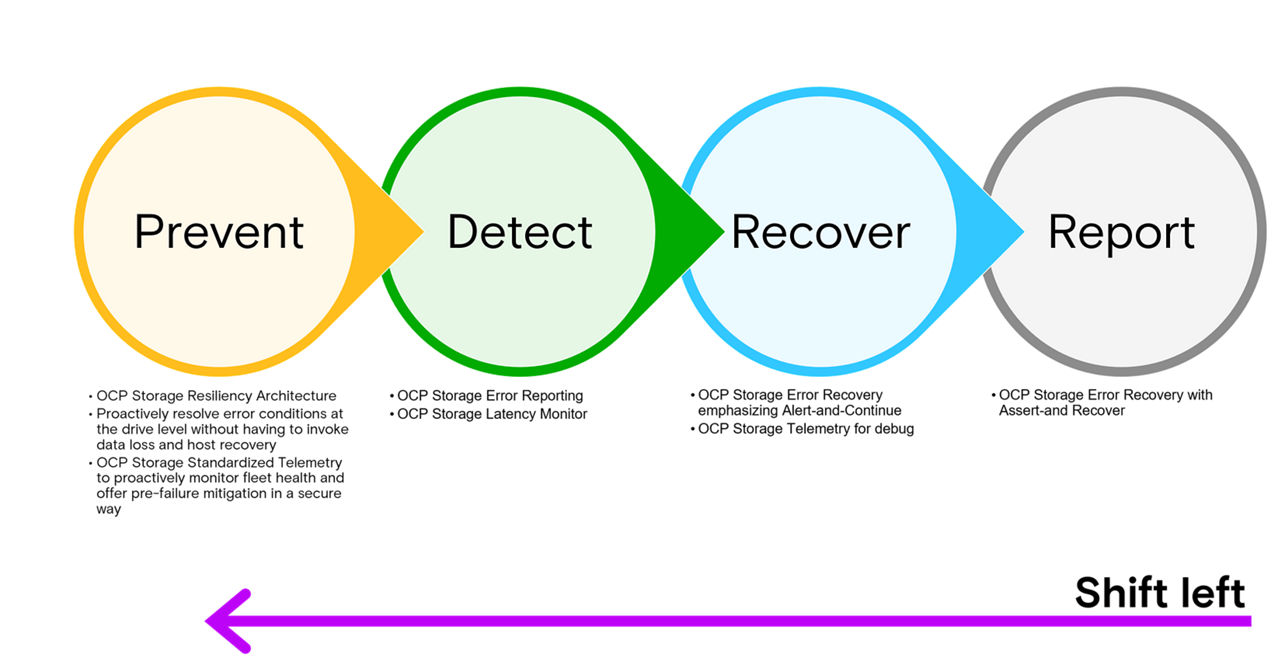
Our vision is a “shift-left” in the efforts needed to create fleet wide high resiliency. Less time debugging and replacing failed drives and more time proactively monitoring fleet health and improving ability to recover without data loss. There are multiple elements to this solution that we’ll discuss and Micron’s view of what might be next in terms of further enhancements.
History of resiliency in SSDs
Before the first version of the OCP Spec, Micron worked hard for seamless intrinsic recovery and self-annealing. These include things such as retiring bad blocks, implementing an internal XOR solution we call Redundant Array of Independent NAND (RAIN), and offering CRC detect and retransmit on the SATA or PCIe bus. We offered SMART information on such events. We worked to collect and monitor this SMART data to help not only monitor overall fleet health and identify potential outliers but also to improve our solutions going forward.

The first effort for vertically integrated solution, which means both the host and device take on elements of making a highly resilient storage subsystem, for enhanced resiliency was championed by Microsoft and first contributed in the OCP Spec V1 where the concept of Error Recovery (logpage C1h) was introduced. This allowed the device to inform the host of an internal panic condition and instruct the host on how to fetch vendor unique debug information as well as how to perform a recovery procedure. The V1 spec supported multiple recovery actions but other parts of the spec (CRASH-4) suggested a FORMAT command., This means that all the data on the device would be erased and unrecoverable, as the only way to recover from an internal panic condition. Microsoft also offered leadership in OCP Spec V1 around the concept of Error Injection for robust vertical integration testing with both host and device participating.
The V2 specification enhanced the recovery procedure by offering additional C1h fields. This specification was the first to introduce the OCP Storage Latency Monitor Feature. This feature allows the drive to self-report high latency I/O events and even include vendor unique debug information. This can be compared against host I/O latency logs to help root cause the problem and if it is a storage device issue provide clues internally to support corrective action.
Some exciting capabilities in the V2.5 specification release recently continue to offer better vertical resiliency integration. Standardizing Telemetry is the biggest element and a majority of the new capabilities in this revision. Prior specifications revisions ultimately lead to each vendor adding unique and proprietary monitoring and debug information that would require either fetching vendor unique logpages or requiring fetching telemetry. The vendor ideally would request a binary file transfer or offer a vendor unique decode tool to generate a human readable output. The Standardized Telemetry in OCP SSD V2.5 spec resolved this by offering ways to both report and decode vendor unique debug with a standardized decode tool. This improves debug efficiency immediately by not needing specialized data capture and decode functions by the host.
The Standardized Telemetry project has created a simple way to collect all the important health data from distributed systems. It uses a single I/O command that works with any compliant storage device. The host can then capture and decode the data from the first telemetry data area. This data has all the details that the host and the vendor need to work together. They can identify the devices that are failing or about to fail, and improve their health monitoring solutions for the future.
Heading forward
Microsoft's Ayberk Ozturk offered a presentation at FMS 2023 on their vision of a future in vertically integrated high resiliency. They expressed a strong desire to have data recovery as part of a panic recovery vs. the current specification request of a FORMAT command. They argued that as storage devices become larger and larger, more tenants might be using a single direct attached drive and it would be desirable post panic to recover with either full (or even partial) data recovery vs. terminating multiple virtual machines. They suggested that this would facilitate concepts around utilizing live migration. Exploring the specifics of such a solution is a good goal for 2024.
A vision
What used to be reporting of asserts and panics has turned into recovery. What was recovery has turned into detection, and what used to be detection has turned into prevention. The classic shift-left. Micron is excited and committed to continue to work with the industry and OCP Storage for this future.
Please reach out to us at Micron with your ideas. It’s a collaboration so let’s work together.
